Scikit-learn è una delle librerie più utilizzate per il machine learning in Python, grazie alla sua semplicità d’uso e alla versatilità. Offre strumenti efficienti per l’analisi predittiva dei dati, costruiti su NumPy, SciPy e Matplotlib. Essendo open-source e con licenza BSD, è ideale sia per progetti personali che per applicazioni commerciali. Questo articolo esplora le sue particolarità, i casi d’uso più comuni e come iniziare a utilizzarla. Approfondiremo le sue funzionalità, con esempi pratici e consigli per sfruttarla al meglio.
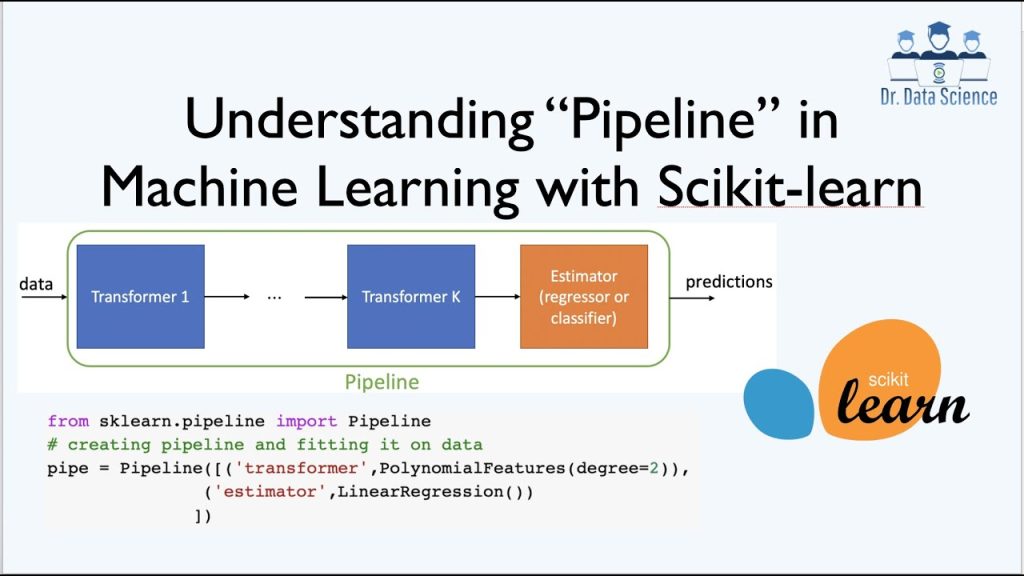
Figura 1: Esempio di pipeline in Scikit-learn.
Introduzione a Scikit-learn
Scikit-learn è una libreria di Python progettata per il machine learning, pensata per essere accessibile a tutti e facilmente integrabile in diversi contesti. La sua forza risiede nella capacità di rendere semplici le operazioni più complesse grazie a un design modulare e un set di API intuitive. Con un ampio supporto della comunità, è diventata un punto di riferimento per chi lavora con i dati.
Caratteristiche principali
- Semplicità e Efficienza: Gli strumenti forniti da scikit-learn sono progettati per offrire ottime prestazioni mantenendo un’elevata semplicità d’uso, riducendo il tempo necessario per sviluppare soluzioni.
- Ampio supporto per algoritmi: Include una vasta gamma di algoritmi, tra cui classificazione, regressione, clustering e riduzione della dimensionalità. Questo consente agli utenti di affrontare un’ampia varietà di problemi con strumenti ben collaudati.
- Compatibilità: Basato su NumPy, SciPy e Matplotlib, garantisce interoperabilità con altre librerie del vasto ecosistema Python, rendendo più semplice l’integrazione in flussi di lavoro complessi.
- Licenza BSD: La sua natura open-source e commercialmente utilizzabile lo rende accessibile a un ampio pubblico, dalle startup alle grandi imprese.

Figura 2: Logo ufficiale di Scikit-learn.
Casi d’uso comuni
Scikit-learn è impiegato in molti settori grazie alla sua flessibilità e all’ampio supporto per numerosi tipi di modelli. Ecco alcuni dei casi d’uso più comuni:
1. Classificazione
Utilizzato per problemi di classificazione, come l’identificazione di e-mail di spam o la classificazione di immagini. Algoritmi come Support Vector Machines (SVM), Naive Bayes, Random Forest e altri sono facilmente implementabili. Grazie a scikit-learn, queste tecniche sono accessibili anche a chi non è esperto.
2. Regressione
Ideale per prevedere valori continui, ad esempio la stima dei prezzi immobiliari o delle vendite future. Modelli come la regressione lineare, l’elastic net o la regressione polinomiale sono già inclusi e configurabili con pochi parametri.
3. Clustering
Perfetto per segmentare dati non etichettati. Algoritmi come K-means, DBSCAN o Agglomerative Clustering aiutano a raggruppare dati simili, utili in scenari come il targeting del marketing o l’analisi esplorativa dei dati.
4. Riduzione della dimensionalità
Tecniche come l’Analisi delle Componenti Principali (PCA) o t-SNE consentono di ridurre il numero di variabili in un dataset, migliorando le prestazioni e semplificando la visualizzazione, specialmente in dataset ad alta dimensionalità.
5. Valutazione dei modelli
Scikit-learn fornisce strumenti integrati per valutare le prestazioni dei modelli con tecniche come la cross-validation, l’analisi delle curve ROC e metriche come accuratezza, precisione, recall e F1-score. Questo assicura che i modelli siano robusti e affidabili.
Come iniziare con Scikit-learn
Installazione
L’installazione è semplice e può essere effettuata con pip:
pip install scikit-learnOppure, se si utilizza conda:
conda install scikit-learn
Assicurati di avere una versione recente di Python e le dipendenze necessarie come NumPy e SciPy.
Primi passi: un esempio pratico
Un esempio comune è l’utilizzo di un modello di classificazione con un dataset integrato. Scikit-learn include molti dataset di esempio per iniziare rapidamente:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Caricamento del dataset Iris
data = load_iris()
X, y = data.data, data.target
# Suddivisione in training e test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Addestramento del modello
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Predizione e valutazione
y_pred = model.predict(X_test)
print("Accuratezza:", accuracy_score(y_test, y_pred))
In poche righe, scikit-learn permette di caricare dati, addestrare un modello e valutarlo. Questo approccio consente di concentrarsi sulla comprensione del problema senza preoccuparsi di dettagli implementativi complessi.
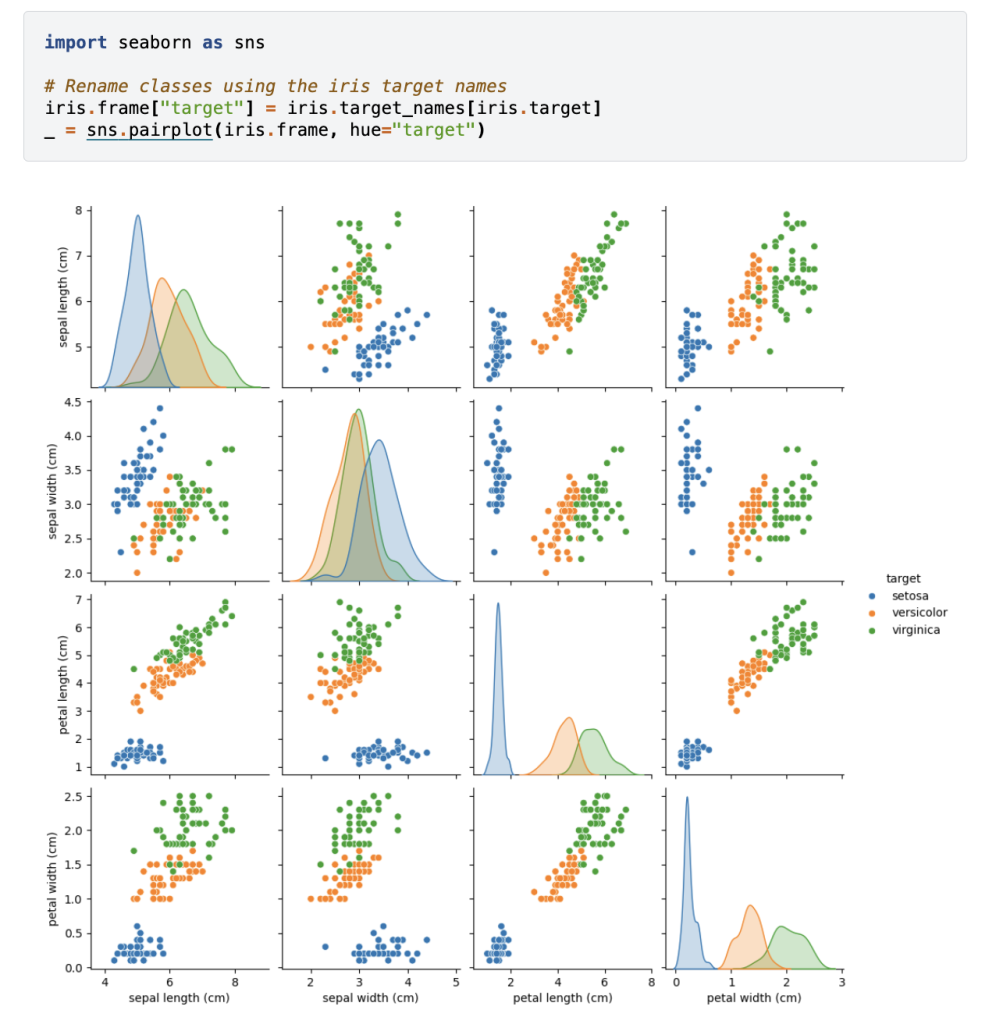
Figura 3: Visualizzazione del dataset Iris.
Documentazione e risorse utili
- Documentazione ufficiale: Una risorsa completa con guide dettagliate, tutorial ed esempi pratici.
- Guide interattive su Kaggle: Piattaforma per praticare il machine learning con dataset reali.
- Repository GitHub di Scikit-learn: Per seguire gli sviluppi della libreria e contribuire alla sua crescita.
Consigli per l’utilizzo
- Conosci i tuoi dati: Prima di applicare modelli, analizza attentamente il dataset, identificando eventuali anomalie, valori mancanti e pattern nascosti.
- Inizia con modelli semplici: Non è necessario partire subito con modelli complessi; spesso quelli più semplici offrono risultati adeguati, riducendo il rischio di overfitting.
- Valuta sempre il modello: Utilizza le metriche appropriate per il tuo problema e considera tecniche come la cross-validation per verificare la robustezza del modello.
- Ottimizza gli iperparametri: Scikit-learn include strumenti come GridSearchCV e RandomizedSearchCV per migliorare le prestazioni del modello in modo sistematico.
- Sfrutta l’ecosistema Python: Integra scikit-learn con altre librerie come Pandas per la manipolazione dei dati o Matplotlib per la visualizzazione.
Conclusione
Scikit-learn è una libreria potente e versatile che consente a chiunque, dai principianti agli esperti, di implementare soluzioni di machine learning in modo rapido ed efficiente. La sua ampia gamma di funzionalità lo rende adatto a molteplici scenari, dalla classificazione alla riduzione della dimensionalità, passando per la valutazione dei modelli. Grazie alla sua semplicità d’uso e alla vasta documentazione disponibile, rappresenta un eccellente punto di partenza per chi desidera esplorare il machine learning con Python.
Se desideri approfondire, non esitare a consultare la documentazione ufficiale e a sperimentare con i dataset forniti dalla libreria stessa.
FAQ
1. Scikit-learn è adatto ai principianti?
Assolutamente sì. Grazie alla sua semplicità e alla documentazione chiara, è una scelta eccellente per chiunque voglia iniziare con il machine learning. Inoltre, gli esempi pratici inclusi rendono l’apprendimento più rapido.
2. Quali sono i requisiti per utilizzare scikit-learn?
Devi avere una conoscenza di base di Python e familiarità con librerie come NumPy e Matplotlib. Per dataset complessi, una comprensione di base della statistica può essere utile.
3. Posso usare scikit-learn per grandi dataset?
Sì, ma per dataset molto grandi potrebbe essere necessario utilizzare tecnologie distribuite come Spark. Scikit-learn è ideale per dataset di dimensioni moderate e per prototipazione rapida.
4. Quali tipi di problemi posso risolvere con scikit-learn?
Classificazione, regressione, clustering, riduzione della dimensionalità e molti altri. Ogni applicazione che richiede analisi predittiva può beneficiare di questa libreria.
5. Quali sono le alternative a scikit-learn?
Alcune alternative includono TensorFlow, PyTorch e XGBoost, che offrono maggiore flessibilità per progetti più complessi o per il deep learning.
6. Scikit-learn supporta il deep learning?
No, scikit-learn è focalizzato su tecniche di machine learning tradizionali. Per il deep learning, è meglio utilizzare librerie come TensorFlow o PyTorch, che sono progettate specificamente per reti neurali e modelli complessi.
