TL;DR
I modelli Titan di Google introducono una memoria neurale innovativa per superare i limiti dei Transformer tradizionali, rendendo possibile l’elaborazione di sequenze di token estremamente lunghe senza perdita di informazioni.
Questa nuova architettura, ispirata al funzionamento del cervello umano, utilizza tre moduli di memoria (breve, lunga e persistente) e ottiene risultati eccezionali nei benchmark per contesti complessi. Titan è pensato per applicazioni specifiche, come la gestione di documenti lunghi, e rappresenta un’evoluzione significativa nel campo dell’IA.
Introduzione
Nell’ambito delle intelligenze artificiali, uno dei principali limiti dei modelli Transformer è la loro incapacità di gestire informazioni a lungo termine, causando così dei problemi di “dimenticanza”. Recentemente, Google ha presentato Titan, una nuova architettura progettata per affrontare questa sfida. Grazie all’implementazione della memoria neurale, i Titan possono registrare e richiamare informazioni in modo più simile al cervello umano, rappresentando un cambiamento cruciale per l’AI aziendale.
Cosa sono i modelli Transformer?
I modelli Transformer rappresentano una pietra miliare nel campo dell’intelligenza artificiale e del natural language processing (NLP). Introdotti per la prima volta nel 2017 da un team di ricercatori di Google con il celebre paper “Attention Is All You Need”, hanno rivoluzionato il modo in cui le macchine comprendono e generano il linguaggio umano.

La loro caratteristica distintiva è il meccanismo di self-attention, che consente al modello di analizzare le relazioni tra i token (parole, frasi o simboli) all’interno di una sequenza. Questo approccio permette di catturare sia le connessioni locali (tra parole vicine) sia quelle globali (tra parti distanti di un testo), superando i limiti delle reti neurali ricorrenti (RNN) e dei loro derivati come le LSTM.
Grazie a questo meccanismo, i Transformer possono:
- Tradurre testi in diverse lingue.
- Generare contenuti coerenti e dettagliati.
- Rispondere a domande complesse.
Esempi di modelli Transformer noti:
- GPT-4 di OpenAI (alla base di ChatGPT).
- BERT e i suoi derivati, come RoBERTa e DeBERTa.
- Gemini di Google DeepMind.
Nonostante il loro successo, i Transformer presentano un limite significativo che emerge quando si trovano ad affrontare testi lunghi o complessi.
Il Problema dei Transformer Tradizionali
Cosa sono i modelli Transformer?
I modelli Transformer rappresentano una pietra miliare nel campo dell’intelligenza artificiale e del natural language processing (NLP). Introdotti per la prima volta nel 2017 da un team di ricercatori di Google con il celebre paper “Attention Is All You Need”, hanno rivoluzionato il modo in cui le macchine comprendono e generano il linguaggio umano.
La loro caratteristica distintiva è il meccanismo di self-attention, che consente al modello di analizzare le relazioni tra i token (parole, frasi o simboli) all’interno di una sequenza. Questo approccio permette di catturare sia le connessioni locali (tra parole vicine) sia quelle globali (tra parti distanti di un testo), superando i limiti delle reti neurali ricorrenti (RNN) e dei loro derivati come le LSTM.
Grazie a questo meccanismo, i Transformer possono:
- Tradurre testi in diverse lingue.
- Generare contenuti coerenti e dettagliati.
- Rispondere a domande complesse.
Esempi di modelli Transformer noti:
- GPT-4 di OpenAI (alla base di ChatGPT).
- BERT e i suoi derivati, come RoBERTa e DeBERTa.
- Gemini di Google DeepMind.
Nonostante il loro successo, i Transformer presentano un limite significativo che emerge quando si trovano ad affrontare testi lunghi o complessi.
Perché dimenticano i dati nei contesti lunghi?
Il problema principale dei Transformer è legato alla gestione della finestra di contesto, ovvero la quantità massima di token che il modello può elaborare contemporaneamente.
1. La finestra di contesto è limitata
Ogni modello Transformer ha una finestra di contesto definita da un numero massimo di token (ad esempio, GPT-4 supporta fino a 32.768 token). Questo limite è imposto da ragioni pratiche legate alla complessità computazionale. Superata questa finestra, il modello non può “vedere” i token che escono dal suo raggio d’azione e, di conseguenza, dimentica informazioni importanti.
2. Complessità quadratica della self-attention
Il meccanismo di self-attention, che calcola le relazioni tra i token, richiede una quantità di risorse che cresce esponenzialmente con l’aumentare della lunghezza della sequenza. In termini pratici:
- Se analizziamo 1.000 token, servono 1 milione di operazioni.
- Con 10.000 token, ne servono 100 milioni.
Questa complessità rende impraticabile l’elaborazione di testi molto lunghi senza compromettere la velocità e l’efficienza.
3. Compressione dei dati contestuali
Per gestire sequenze più lunghe, i modelli tendono a comprimere le informazioni nella finestra di contesto. Tuttavia, questo processo porta spesso alla perdita di dettagli importanti, specialmente in testi che richiedono una comprensione precisa di relazioni tra eventi distanti.
- Esempio pratico: Un modello che legge un romanzo lungo potrebbe perdere informazioni su eventi accaduti all’inizio della storia, generando risposte incoerenti o inventando dettagli inesistenti (le cosiddette “allucinazioni”).
4. Mancanza di memoria a lungo termine
I Transformer tradizionali non hanno un sistema per ricordare informazioni al di fuori della finestra di contesto. Ogni richiesta è elaborata isolatamente, senza un meccanismo che permetta al modello di conservare e richiamare dati storici. Questo è un problema evidente nei compiti che richiedono una visione globale o un accesso continuo a informazioni passate.
In sintesi, il problema dei Transformer tradizionali si riduce alla loro incapacità di scalare in modo efficiente su sequenze molto lunghe. Questo limita la loro utilità in applicazioni come l’analisi di documenti estesi, la gestione di archivi storici e il ragionamento su contesti complessi. Ed è qui che entrano in gioco i modelli Titan, progettati per superare queste barriere.
Come Funzionano i Titan di Google
I modelli Titan rappresentano un’innovazione significativa nell’elaborazione di sequenze di dati estremamente lunghe, grazie all’introduzione di una memoria neurale modulare. Questo sistema è progettato per superare i limiti dei Transformer tradizionali, che soffrono di perdite di informazioni e alta complessità computazionale.
La memoria a lungo termine e il concetto di “sorpresa”
Una caratteristica centrale dei Titan è la capacità di gestire una memoria a lungo termine (Long-Term Memory), che opera indipendentemente dalla finestra di contesto principale. Questo modulo di memoria è progettato per apprendere e ricordare nuove informazioni in tempo reale, utilizzando un approccio ispirato al funzionamento del cervello umano.
Il principio chiave alla base di questa memoria è il concetto di “sorpresa”, un meccanismo che consente al modello di identificare quali informazioni sono abbastanza significative da essere memorizzate.
Come funziona la sorpresa:
Durante l’inferenza, il modello analizza l’input calcolando il gradiente della funzione di perdita rispetto ai token.
Se il gradiente associato a un’informazione è elevato, significa che quell’informazione è nuova, inaspettata o importante. Questo segnala al modello di conservarla nella memoria a lungo termine.
Esempio pratico:
Un modello che analizza una cronologia di eventi potrebbe considerare il testo “Mario ha camminato verso casa” come prevedibile e quindi non memorizzarlo. Tuttavia, se il testo cambia in “Mario ha camminato verso casa e ha incontrato un leone”, l’informazione viene classificata come sorprendente e memorizzata.
Meccanismi di decadimento adattivo
Per evitare il sovraccarico della memoria, i Titan implementano un sistema di decadimento adattivo. Ogni informazione memorizzata ha un parametro di “durata”, che determina per quanto tempo resterà rilevante. Questo meccanismo garantisce che la memoria sia dinamica e flessibile, eliminando gradualmente i dati che non sono più utili.
Il funzionamento del decadimento adattivo
Le informazioni che diventano irrilevanti rispetto al contesto corrente vengono eliminate.
Se nuove informazioni confermano o rafforzano un dato già memorizzato, il decadimento viene rallentato, permettendo al dato di persistere più a lungo.
Al contrario, dati contraddittori o ridondanti decadono rapidamente.
Esempio pratico
Un modello che analizza le prestazioni finanziarie di un’azienda potrebbe memorizzare una notizia rilevante come “Profitti trimestrali in crescita”. Tuttavia, se il contesto si sposta su un’altra azienda o settore, l’importanza di quel dato diminuisce e viene gradualmente dimenticata.
Le Tre Architetture dei Titan
I Titan sono progettati per adattarsi a diversi contesti attraverso tre varianti principali, ciascuna con un approccio unico alla gestione della memoria. Queste architetture permettono di bilanciare flessibilità, efficienza e accuratezza in base alle esigenze specifiche.
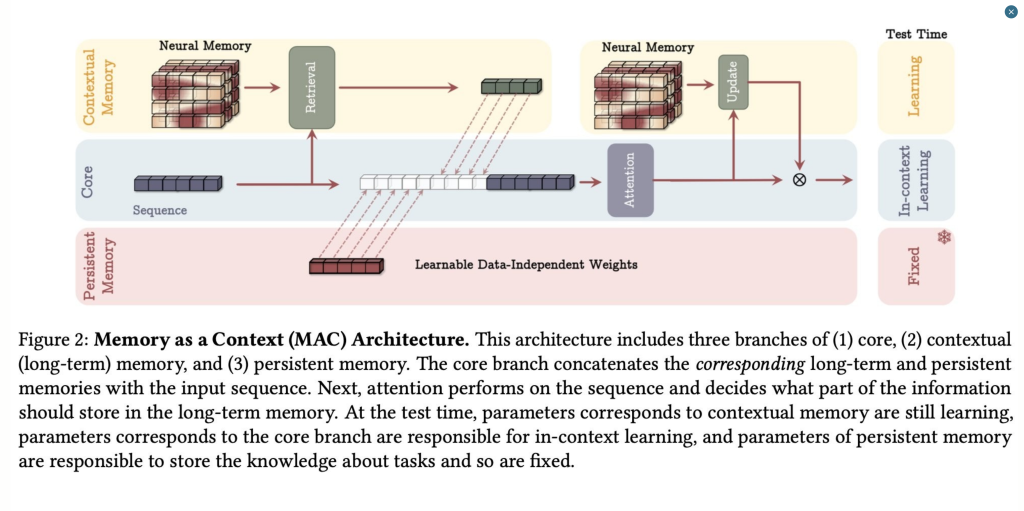
1. Memory as a Context (MAC)
Nella variante Memory as a Context, la memoria a lungo termine viene trattata come parte del contesto corrente. Le informazioni memorizzate vengono integrate direttamente nella rappresentazione della sequenza attuale, formando un contesto esteso che combina dati storici e immediati.
Caratteristiche principali:
La memoria a lungo termine è concatenata al contesto attuale, espandendo la finestra di attenzione.
Utilizza il concetto di sorpresa per identificare quali informazioni memorizzare.
Adotta il decadimento adattivo per gestire in modo efficiente lo spazio disponibile.
Esempio:
In un documento scientifico, MAC potrebbe recuperare informazioni apprese in paragrafi precedenti e integrarle con il contesto attuale per rispondere a una domanda complessa.
Prestazioni:
Questa variante offre eccellenti risultati nelle attività che richiedono una comprensione globale del testo, come il benchmark BABILong.
2. Memory as a Gate (MAG)
La variante Memory as a Gate introduce un meccanismo di gating per bilanciare l’influenza delle memorie a breve e lungo termine. Il modello decide dinamicamente se rafforzare le informazioni memorizzate o sostituirle con nuovi dati in base alla rilevanza del contesto corrente.
Caratteristiche principali:
Il gate funge da filtro non lineare che regola il contributo delle memorie.
Limita l’impatto di dati contraddittori o irrilevanti.
Aggiorna gradualmente la memoria a lungo termine, sostituendo i dati obsoleti.
Esempio:
Se un modello analizza una sequenza recente che contraddice informazioni precedenti (ad esempio, una rettifica su un evento storico), il gate può ridurre l’influenza della memoria a lungo termine e incorporare i nuovi dati.
Prestazioni:
MAG offre risultati leggermente inferiori rispetto a MAC su sequenze molto lunghe, ma è più adatto a contesti dinamici dove le informazioni cambiano frequentemente.
3. Memory as a Layer (MAL)
La variante Memory as a Layer tratta la memoria a lungo termine come uno strato separato della rete neurale. Questo modulo comprime le informazioni storiche e le rende disponibili al modello in un formato compatto e rilevante.
Caratteristiche principali:
La memoria a lungo termine agisce come un livello autonomo che condensa i dati storici.
Filtra e seleziona solo le informazioni più utili, riducendo la ridondanza.
Minimizza il carico computazionale sul modulo di attenzione principale.
Esempio:
In un documento legale, MAL potrebbe comprimere i dati di clausole precedenti, mantenendo solo i punti essenziali per il paragrafo corrente.
Prestazioni:
Questa variante è meno performante rispetto a MAC e MAG nei test empirici, ma risulta efficace in scenari in cui è necessario ridurre la complessità computazionale.
Prestazioni dei Titan
I benchmark BABILong e S-NIAH
I modelli Titan hanno dimostrato prestazioni eccezionali in test progettati per valutare la capacità di elaborare sequenze di token estremamente lunghe. Tra i benchmark più significativi:
- BABILong (Benchmark for Abstraction and Reasoning on Long Sequences):
- Questo test misura la capacità di un modello di ragionare attraverso fatti distribuiti su documenti estesi.
- Titan, nella variante Memory as a Context (MAC), ha superato modelli di grandi dimensioni come GPT-4 e Llama-3 su questa metrica, dimostrando una comprensione profonda anche di documenti molto lunghi.
- S-NIAH (Single Needle In A Haystack):
- Valuta la capacità del modello di recuperare informazioni specifiche e rilevanti da sequenze lunghe fino a 16.000 token.
- Titan ha mostrato un’elevata accuratezza nel recupero di dettagli precisi, risultando particolarmente efficace rispetto ai Transformer tradizionali.
Risultati chiave:
- Titan riesce a gestire fino a 2 milioni di token grazie alla memoria a lungo termine, senza aumentare significativamente i costi computazionali.
- Anche con dimensioni relativamente ridotte (400 milioni di parametri), i Titan hanno battuto modelli con miliardi di parametri nei contesti lunghi.
Confronto Titan Google con GPT-4 e altri modelli
Sebbene GPT-4 sia considerato uno dei modelli più avanzati per generazione di testo e chatbot, Titan offre vantaggi in compiti specifici:
- Gestione di sequenze lunghe: Titan eccelle nel mantenere informazioni distribuite su ampie finestre di contesto, superando GPT-4 in accuratezza su testi estesi.
- Efficienza computazionale: Grazie all’uso della memoria neurale, Titan gestisce compiti complessi senza richiedere miliardi di parametri, mantenendo bassi i costi computazionali.
- Focus sul recupero delle informazioni: Titan è progettato per compiti di recupero e ragionamento in contesti professionali, mentre GPT-4 è ottimizzato per interazioni più brevi e generazione creativa di testo.
Limiti rispetto a GPT-4:
Titan non è pensato per attività di tipo Instruct (chatbot, risposte creative o conversazioni brevi), dove GPT-4 mantiene un vantaggio. Tuttavia, nei contesti aziendali e analitici, Titan si dimostra una soluzione più robusta.
Applicazioni e Futuro dei Titan
I casi d’uso principali
I Titan si distinguono per la loro capacità di scalare su compiti specifici che richiedono la gestione di contesti lunghi e complessi. Tra i principali campi di applicazione:
- Analisi di documenti estesi: Perfetti per gestire testi lunghi come documenti legali, report scientifici o archivi storici, dove è cruciale ricordare informazioni distribuite nel tempo.
- Previsioni da serie temporali: Utilizzabili in settori come la finanza o la meteorologia, dove i modelli devono elaborare grandi quantità di dati storici per produrre previsioni accurate.
- Compiti analitici complessi: Ideali per attività che richiedono ragionamenti su contesti ampi, come rispondere a domande complesse o individuare correlazioni su sequenze lunghe.
Possibili implicazioni per modelli come Gemini e ChatGPT
- Gemini di Google DeepMind: Nonostante le potenziali sinergie, Titan non sembra destinato a sostituire Gemini nel breve termine. Tuttavia, l’integrazione delle loro tecnologie potrebbe rappresentare un passo avanti verso modelli più versatili.
- ChatGPT di OpenAI: Titan non è un concorrente diretto per ChatGPT, ma potrebbe influenzare il modo in cui i modelli futuri affrontano problemi di memoria e contesto nei chatbot, portando a interazioni più approfondite su contesti estesi.
Conclusioni e Prospettive
Titan sostituirà i Transformer?
I modelli Titan non sono pensati per sostituire completamente i Transformer tradizionali, ma piuttosto per affiancarli in compiti specifici. L’approccio modulare della memoria neurale si rivela particolarmente efficace in contesti professionali e analitici, dove la gestione di sequenze lunghe è essenziale.
L’importanza di modelli specializzati nel futuro dell’IA
Il futuro dell’intelligenza artificiale sembra orientarsi verso una specializzazione dei modelli:
- Modelli come Titan eccelleranno in ambiti di analisi complessi.
- Altri, come i nano-modelli, saranno ottimizzati per operare su dispositivi mobili.
- I modelli generalisti (es. GPT-4) continueranno a dominare nelle applicazioni creative e di uso generale.
Questa frammentazione riflette una maturazione del settore, in cui non ci sarà un singolo modello dominante, ma un ecosistema di soluzioni altamente ottimizzate.
FAQ
Cosa distingue Titan dai Transformer tradizionali?
Titan introduce una memoria neurale modulare che opera indipendentemente dalla finestra di contesto principale, permettendo di gestire sequenze lunghe senza perdita di informazioni e con costi computazionali ridotti.
Titan può essere usato per chatbot come ChatGPT?
Non direttamente. Titan è ottimizzato per compiti analitici su sequenze lunghe, mentre chatbot come ChatGPT sono progettati per conversazioni brevi e risposte creative.
Quali sono i limiti dell’architettura Titan?
- Non è ancora chiaro come Titan si comporti in applicazioni generative su larga scala.
- Le sue prestazioni devono essere testate su modelli con miliardi di parametri per confronti più diretti con Transformer avanzati.
Perché i Titan non usano miliardi di parametri?
Grazie alla memoria neurale, Titan riesce a ottenere risultati competitivi con solo centinaia di milioni di parametri, riducendo costi di addestramento e inferenza.
Google integrerà Titan in Gemini?
Non è stato ancora annunciato ufficialmente. Tuttavia, l’architettura Titan potrebbe essere una naturale evoluzione di Gemini, offrendo nuove capacità nella gestione di contesti lunghi.
Conclusione
I Titan di Google rappresentano un’evoluzione fondamentale nella progettazione di modelli di intelligenza artificiale, limitando le inefficienze e aprendo la strada a nuove applicazioni. Le aziende che desiderano implementare soluzioni di AI dovrebbero considerare questi modelli per le loro capacità uniche di apprendere e gestire informazioni in contesti complessi. È tempo di ripensare alle possibilità che l’intelligenza artificiale può offrire.
